Failover is a critical aspect of web hosting that ensures that your website remains accessible in the event of a server or network failure. It involves automatically switching to a backup server or network when the primary one fails, minimizing downtime and ensuring continuity of service.
In this short post, we’ll explore what failover is, how it works in web hosting, and what you can do to ensure that your website remains accessible at all times.
What is Failover?
Failover is the process of automatically switching to a backup server or network in the event of a primary server or network failure. This ensures that your website remains accessible and minimizes downtime, which is critical for maintaining a positive user experience and preventing revenue loss.

Failover can be used in various networking services, including DHCP, SQL, HADR, DNS, RDS etc. The primary goal of failover is to ensure continuity of a specific service and prevent downtime.
– DHCP Failover
Dynamic Host Configuration Protocol (DHCP) is a protocol used to automatically assign IP addresses to devices on a network. DHCP failover is used to provide redundancy and ensure that IP addresses are always available for clients. When one DHCP server fails, another server can take over and provide IP addresses to clients in its place, without any noticeable downtime. DHCP failover can be configured in two ways: hot standby and load balancing.
– SQL Failover
Structured Query Language (SQL) is a database management system used to manage and manipulate relational databases. SQL failover can be used to provide high availability and prevent data loss in the event of a primary server failure. With SQL failover clustering, multiple servers work together to provide a common set of services and data, and if one server fails, another server can take over and continue providing the same services. This is accomplished through the use of a failover cluster instance (FCI) that allows multiple servers to access the same database.
– HADR Failover
High Availability Disaster Recovery (HADR) is a solution that provides continuous data availability and rapid data recovery in the event of a disaster. HADR failover is used to ensure that critical applications and services are always available, even in the event of a disaster. With HADR failover, a secondary site or server takes over from the primary site or server in the event of a disaster, providing continuity of service and preventing data loss. This is achieved through a process called database mirroring, which involves copying data to a secondary server and keeping it synchronized with the primary server.
– DNS Failover
Domain Name System (DNS) is a critical component of web hosting that translates domain names into IP addresses. DNS failover is used to ensure that domain names remain accessible and that requests are always directed to an available server. With DNS failover, requests are automatically redirected to an available server in the event of a primary server failure, ensuring that websites remain accessible.
– RDS Failover
Relational Database Service (RDS) is a web service offered by Amazon Web Services (AWS) that makes it easy to set up, operate, and scale a relational database in the cloud. RDS failover is used to ensure high availability and prevent data loss in the event of a primary database instance failure. With RDS failover, a secondary database instance takes over from the primary instance in the event of a failure, providing continuity of service and preventing data loss.
How does Failover Work in Web Hosting?
In web hosting, failover typically involves setting up redundant servers or networks that can automatically take over (without any noticeable interruption in service and downtime) when the primary one fails. This is often accomplished through the use of load balancers, which distribute traffic across multiple servers or networks, and failover software, which monitors the primary server or network for failures and switches to the backup one when necessary.

In addition to oad balancing, failover can be achieved through the clustering, and DNS-based redirection. The principle behind all there remains the same though – the secondary server is often a replica or a redundant copy of the primary server, and it takes over when the primary server experiences issues like hardware failures, software crashes, network outages, or excessive traffic.
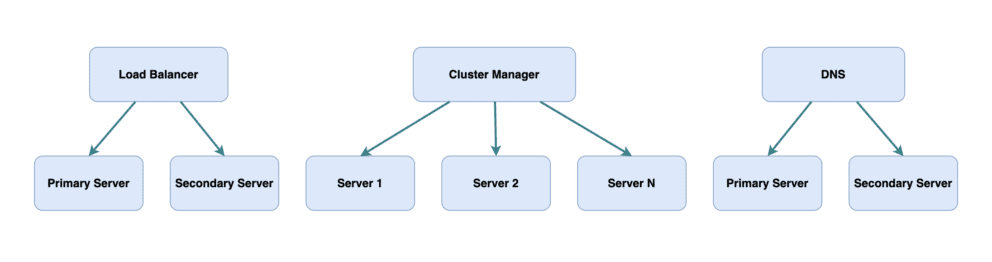
– Load Balancing:
Imagine a load balancer as a central point that distributes incoming network traffic across multiple servers. The load balancer sits in front of your primary and secondary (failover) servers, monitoring their health. When the primary server goes down, the load balancer detects this and routes traffic to the secondary server.
– Clustering:
In a clustered setup, multiple servers work together to provide redundancy and high availability. A cluster can include primary and secondary servers, as well as additional nodes. If the primary server fails, the secondary server or another node in the cluster takes over.
– DNS-based Redirection:
In this method, a DNS service is used to monitor the health of your primary and secondary servers. If the primary server goes down, the DNS service automatically redirects traffic to the secondary server by changing the IP address associated with your domain name.
Implementing a failover system in web hosting helps to ensure that a website or application remains accessible and functional, even in the face of unexpected issues, thus minimizing the negative impact on user experience and preventing potential revenue loss.
Why Servers and Networks Fail?

There are several common causes of server or network failures, including:
- Hardware or software issues
- Power outages or other electrical problems
- Natural disasters, such as earthquakes or floods
- DDoS attacks or other malicious activity
- Human error, such as misconfiguration or accidental deletion of data
What can I do to Ensure Failover for my Website?
There are several steps you can take to ensure failover for your website, including:
- Choosing a web hosting provider with a robust and reliable network infrastructure
- Setting up redundant servers or networks to ensure that there is always a backup available
- Using load balancers to distribute traffic across multiple servers or networks
- Monitoring your website’s performance and network status regularly to identify and address any issues promptly
- Testing your failover system regularly to ensure that it works as expected
Popular Failover Software for Web Hosting
There are several popular solutions used for implementing failover in web hosting. These tools often provide load balancing, clustering, and DNS-based redirection features. Among some popular ones:
- HAProxy: HAProxy is a widely used, high-performance load balancer and proxy server. It can be used for distributing web traffic to multiple servers to ensure high availability and failover support
- NGINX: NGINX is a powerful web server, reverse proxy, and load balancer. It can be configured to distribute traffic among multiple servers, providing failover capabilities and improving overall performance.
- Keepalived: Keepalived is a Linux-based solution for managing high availability and load balancing using the Linux Virtual Server (LVS) and the Virtual Router Redundancy Protocol (VRRP). It can help set up failover for web hosting by monitoring server health and directing traffic accordingly.
- Apache HTTP Server with mod_proxy_balancer: Apache HTTP Server is one of the most widely used web servers. It can be extended with the mod_proxy_balancer module, which adds load balancing and failover support by distributing incoming requests among multiple backend servers.
- Amazon Route 53: Amazon Route 53 is a highly scalable DNS service provided by Amazon Web Services (AWS). It can be used to implement DNS-based failover and load balancing for web hosting by routing traffic to healthy servers based on predefined health checks.
- Cloudflare Load Balancing: Cloudflare offers a load balancing solution that distributes traffic across multiple servers, ensuring high availability and automatic failover. It can be used in conjunction with their CDN and security features to improve website performance and resilience.
These are just a few examples that can be used to implement a sophisticated failover in web hosting. Depending on your specific requirements and infrastructure, you might find that one of these tools is more suited to your needs than others.
FAQ:
How quickly does failover happen?
Failover typically happens within seconds or minutes, depending on the complexity of the setup and the speed of the failover software.
Can failover prevent all downtime?
While failover can minimize downtime, it cannot prevent all downtime, especially in cases where there are widespread network or infrastructure failures.
Do I need to set up my own failover system, or does my web hosting provider handle it?
This depends on the web hosting provider and the specific hosting plan you choose. Some providers may offer failover as part of their service, while others may require you to set it up on your own.
How can I test my failover system?
You can test your failover system by simulating a failure and observing how the backup server or network takes over. This can be done manually or through automated testing tools.
How much does failover cost?
The cost of failover can vary depending on the web hosting provider and the specific setup. Some providers may offer failover as part of their service, while others may charge extra for it. Additionally, setting up redundant servers or networks can be more expensive than using a single server or network. It’s important to weigh the costs against the benefits of failover to determine if it is a worthwhile investment for your website.
Notable brands:
Related terms:
- Redundancy: Redundancy refers to the practice of having extra components or systems that can take over the function of failed components or systems, in order to ensure continuity of service.
- Load balancing: Load balancing involves distributing incoming network traffic across multiple servers, in order to prevent any one server from becoming overloaded and to improve overall system performance and reliability.
- High availability: High availability refers to the ability of a system to provide uninterrupted service and minimize downtime, typically achieved through redundancy, load balancing, and other techniques.
- Disaster recovery: Disaster recovery is the process of restoring a system or network to its original state following a catastrophic event, such as a natural disaster, cyber attack, or hardware failure.
- Fault tolerance: Fault tolerance refers to a system’s ability to continue operating in the event of a hardware or software failure, typically achieved through redundancy and other techniques.
- Resilience: Resilience refers to a system’s ability to recover from and adapt to unexpected events, such as hardware failures, network outages, or cyber attacks.
- Replication: Replication involves copying data or software to multiple servers or devices, in order to improve performance, reliability, and data availability.
- Cluster: A cluster is a group of interconnected servers or computing devices that work together to provide a common set of services or applications.
- Backup: Backup refers to the process of copying and storing data or software in a separate location or device, in order to protect against data loss or corruption.
- Virtualization: Virtualization involves creating a virtual version of a computing environment, such as a server or network, in order to improve efficiency, scalability, and flexibility.


 Explained in Simple Terms")

